Published August 16, 2012
Data serialization can be as easy as two VIs
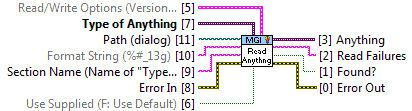
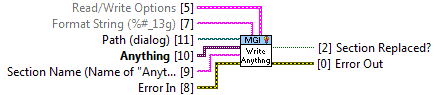
Almost every application needs to save information in files, and the question we developers face is what file format to use. Configuration files (aka .ini files) have the advantages of flexibility, human readability, familiarity to users, and natural mechanisms for forward and backward compatibility. Until now, their main weakness has been performance for even modest data sets. The MGI Read/Write Anything VIs provide huge performance gains (in some cases, more than 500x) for reading and writing configuration style files compared to existing solutions. This opens up the possibility of using them for medium and large data files, not just for small configuration files. With the availability of these VIs, MGI thought it would be useful to perform a fresh analysis of many different file format options using many different design criteria. You’ll find that analysis just below. Following the analysis is a description of how the MGI Read/Write Anything VIs are written and a list of their limitations that we’re currently aware of. The VIs are free and unlocked, so if you want more details, you can always just look at the source code!
Choosing File Format(s) for your Applications
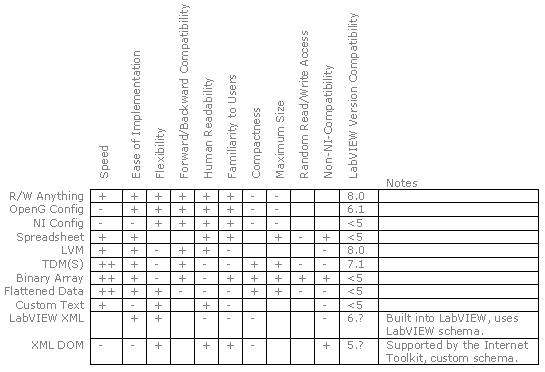
There are many considerations when choosing file formats, and different criteria will have greater or lesser importance depending on the application. In this analysis, we’ve chosen to look at the following criteria:
| Metric | Considerations |
|---|---|
| Speed | Speed variation comes from differences in compactness, random access, minimum read size, and type of conversion, if any, needed between the memory representation and the disk representation. |
| Ease of Implementation | Some formats automatically handle many data types while others require manual coding. |
| Flexibility | Some formats are only useful for specific types of data. |
| Forward/Backward Compatibility | As an application evolves with time, some file formats make it easy to deal with changing data formats. |
| Human Readability | Some text formats are designed for human readability and modification. |
| Familiarity to Users | It’s valuable to use file formats that your users already understand. |
| Compactness | Text formats require more disk space than binary formats to represent the same amount of data. |
| Maximum Size | Some files are limited in size because the whole file needs to be read or written at once. Other files have sizes or offsets within them that are 16 or 32 bit integers. |
| Random Read/Write Access | Some formats used fixed field widths and others use lookup tables to allow accessors to quickly locate data within a file. |
| Non-NI-Compatibility | Some formats, such as spreadsheet text, are directly readable by other applications. Others may be difficult or impossible to read. |
| LabVIEW Version Compatibility | First version of LabVIEW that supports the file format explicitly. |
MGI’s rating of these criteria for eleven different file formats are given in the table below.
As you can see, the new Read/Write Anything file format has a unique combination of strengths that we think make it useful for many applications.
Technical Details
- The only datatypes that cannot be wired directly into these VIs are classes. For classes, create methods for storage and retrieval and use these VIs inside the methods. An example of this technique is available Read/Write Anything with Classes
- When
Write Anything.viis passed a cluster, it converts each element to a string to be written to file.Read Anything.vitakes the type string of the cluster fromVariant to Flattened String, builds the data string either from file if the element exists or from the element’s default data if it does not, and reconstructs the cluster with Flattened String to Variant. In this manner a complex cluster can be recreated even if only a few (or none) of its elements exist in the file. Since elements are referenced by name, if the name of the element in the cluster has changed, it will not be found in the file and will be supplied with the default data for that type. - Numerics will be formatted as the number they represent according to the
Format String (%#_13g)parameter. The default,%#_13g, will allow up to 13 significant digits, but will only include those necessary, so you don’t get trailing zeros. - Arrays of numerics will be on one line and will be comma delimited. You can change the comma to a space by modifying the source code, but then you’ll have problems with arrays of complex numbers. Arrays will display their dimension and size within less than and greater than characters. A three dimensional array would be represented as
<4,7,1>with 4, 7, and 1 being the respective dimension sizes. - Enums are formatted into the string that represents the value. The elements of an array of enums will each have its own line, as do strings, paths and booleans.
- Strings will be formatted in their
Normal Displayformat. - Paths will be formatted as their
path to stringequivalent. - Booleans will be formatted as
TRUEorFALSE. - All other datatypes will be formatted as the hexadecimal representation of their binary denoted by the header
0x. - The VIs will “play nice” with existing .ini files; only the specified section in the file will be modified.
- Any character is allowed in a control name or string or path value. However, to ensure proper formatting and parsing of .ini files, carriage returns, line feeds, and equal signs will be replaced when written to file and properly converted back when read from file. To avoid costly backspace notation and replacement (the normal but slow method of such operations), these three characters are replaced by a special string. The string is composed of the name of the character with a series of random, non-displayable characters in the middle, designed to never be encountered elsewhere (possible, I guess, but very unlikely).
- The whole file is read or written at once, so system RAM limits file size.
- Recursion is implemented using queues rather than VI Server.
- At the lower level, VIs in the
vi.lib/utility/VariantDataTypedirectory are used. These VIs, available since LabVIEW 8.0, provide a faster way to analyze data types in variants. - Performance of the Read/Write Anything VIs is much improved over the OpenG Config file tools which we have been using in earlier projects. Here are some test results that show particularly large performance gains.
| 10x10 2D Array of Cluster of Boolean and Numeric | Seconds | Factor |
|---|---|---|
| Write Anything | 0.0235 | 1.0 |
| OpenG Write | 12.6880 | 539.9 |
| Read Anything | 0.0158 | 1.0 |
| OpenG Read | 3.2625 | 206.5 |
| Cluster of All Data Types and Two Element 1D Array of All Data Types |
Seconds | Factor |
|---|---|---|
| Write Anything | 0.0103 | 1.0 |
| OpenG Write | 5.4711 | 531.2 |
| Read Anything | 0.0079 | 1.0 |
| OpenG Read | 0.9179 | 116.2 |